更新时间:2016-12-28 09:00 浏览: 次 作者:admin 文章来源: 机器之心
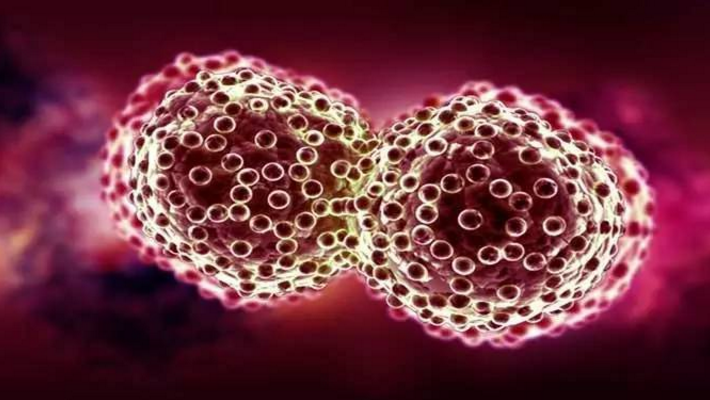
Rick Stevens 表示,首个先进癌症计算解决方案的联合设计(Joint Design of Advanced Computing Solutions for Cancer,JDACS4C)「成果」将于 2017 年第二季度的某个时间公开。JDACS4C 一共有三个试点项目,Rick 领导了其中之一,将深度学习(DL)应用到癌症治疗中去。这些项目不仅可以推进癌症研究和治疗,而且可以提高深度学习的能力和基础架构,最终着眼于百亿亿次计算机的研究,DOE 将对这些项目提供部分的资金支持。
无论以哪种标准,美国对抗癌症(U.S. War on Cancer)和 Precision Medicine Initiative(精准医学计划,PMI)都颇具野心。过去,对抗癌症一直没有很明显的进步,但也不是说没有取得很多成绩。
只是现在看来前景更为光明。生物医学的进步和下一代领先计算机的兴起(百亿亿次计算机的开发)推动着癌症治疗的发展。深度学习和数据驱动科学的快速发展,使许多人对前景报以乐观的态度,所以 2016 全球超级计算机大会重点关注精准医疗和 HPC 的作用就是偶然了。
三个 JDACS4C 试点项目,包括从分子层面到人口规模方面的诸多研究,以支持 CANcer 分布式学习环境项目(CANcer Distributed Learning Environment project):这些工作旨在洞察可扩展机器学习工具;通过深度学习、模拟和分析技术,减少治疗时间;为未来计算方案提供信息。也希望能建立「有效利用日益增长的数据和与癌症相关数据的多样性来打造预测性模型,为接下来的癌症研究提供一个新的范式,更好地理解疾病并最终提供指导,支持基于个体预期治疗结果的决策,Rick 说。
这些都是远大的目标。因此想要总结出 JDACS4C 的准确谱系,确实有点麻烦,广义上来看,它属于 PMI,美国国家癌症研究所的癌症登月计划,也集中在 美国国家战略计算计划(NSCI)之下。Stevens 指出,早在几年前就开始讨论创建这个大项目框架了,8 月拿到了第一笔资金。以下是三个试点项目的简介:
RAS 分子项目: 这个项目((Molecular Level Pilot for RAS Structure and Dynamics in Cellular Membranes)旨在开发新的计算方法,支持 RAS 计划下已经完成的研究,最终完善我们对癌症中的 RAS(基因家族)及其相关信号通路作用的理解,识别 RAS 蛋白膜信号复合物中独有的新治疗靶点。
临床前筛选: 该项目(Cellular Level Pilot for Predictive Modeling for Pre-clinical Screening)将开发「基于源自人源性肿瘤组织异种移植实验性生物数据的机器学习、大规模数据和预测模型」。旨在创建一个反馈回路,其中,实验模型指导计算模型的方案。这些预测模型可能给癌症治疗的指明了新目标,并帮助确定新的治疗方法。
人口模型:这个项目(Population Level Pilot for Population Information Integration, Analysis and Modeling))旨在建立一个可扩展的框架,能够高效提取、延展、整合及 构建癌症患者的病例信息。这样的一个「引擎」应用在医疗保健的许多方面(转移、成本控制、研究等),将会十分强大。
显而易见的是,这么复杂的工作需要很多组织的配合。国家癌症研究所的部门包括生物医学信息和信息技术中心(CBIIT),癌症治疗诊断部(DCTD),癌症控制和人口科学部(DCCPS)和弗雷德里克国家癌症研究实验室(Frederick National Laboratory for Cancer Research)。也有四个美国能源部国家实验室被正式分派从事这个项目,这四个实验室分别是阿贡国家实验室(Argonne National Laboratory)、橡树岭国家实验室(Oak Ridge National Laboratory)、劳伦斯利弗莫尔国家实验室(Lawrence Livermore National Laboratory)和洛斯阿拉莫斯国家实验室(Los Alamos National Laboratory)。
当所有的试验项目放在一起时,Stevens 指出,我们意识到每个项目都需要深度学习,而且需要它的各种不同用途。因此,我们的想法是,既要构建软件环境和网络拓扑,也要建造这三个项目所需的所有东西,所以我们不会复制。研究人员也定义了关键标准——与我们用来解决不同癌症子问题资源相匹配的、易于处理的深度学习问题。
早期的第一步是吸引供应商参与,这充分地证明了 Stevens 所说的话,因为几乎所有的主要 HPC 供应商都在积极地加速深度学习路线图。大多数人认为 JDACS4C 试点项目是学习和完善的机会。Stevens 说,JDASC4C 已经与英特尔、Cray、NVIDIA、IBM 等公司达成了合作关系。
「所有的实验室都配备了 DGX-1,并且 NVIDIA 已经为不同 GPU、Pascal 等优化了大多数的通用框架。我们在 DGX-1 上运行的任何东西都可以很容易地实现分布式。英特尔有自己的长远计划,并且并不是所有的这些计划都是公开的。我可以表明的是,我们正在与英特尔的所有适合的部门合作。」Stevens 说,他是 ANL 研究员和临床前筛选项目的领导者。
事实上,英特尔一直很忙,忙于购买 Nervana(一个用于深度学习的完整平台),最近又推出了扩展计划。Stevens 说:「他们谈论到为机器学习而优化的 Knights X 系列的版本。Knights Mil 是他们的线路图的第一个版本,」这个芯片巨头还在 SC16 上推出了深度学习推理加速卡;它是用于神经网络加速的基于现场可编程门阵列(field-programmable gate array (FPGA))的软硬件解决方案。Stevens 认为英特尔像 NVIDIA 一样,正在制定一个应用战略。
他说:「英特尔非常想尝试确定一种战略,以区分训练和推理平台之间的某些级别。大多数深度学习系统现在在『quasi』上做推理,它比用于训练的平台更小。英特尔希望确保『未来的 IA 架构擅长推理』」。
不足为奇的是现在人们花费了大量的精力用于评估来自谷歌、微软、Facebook 等公司的深度学习框架。Stevens 说:「我们也正在评估哪些框架最适合解决我们的问题,我们正在与供应商一起在硬件上优化它们。同时我们也与 Livermore 有合作关系,他们有一个内部的被称为 LBANN 的项目,该项目旨在构建一个可扩展的人工神经网络框架。」
「该计划是想以一种独立于框架的方式去开发我们的模型,所以我们可以在不需要重新编码我们的模型的情况下交换框架。这是一个非常常见的深度学习方法,其中有一个脚本层(scripting layer)可以捕获您的模型的表示(用于训练和管理数据的元算法(meta algorithms)等),我们同时与学术界和 NVIDIA 在顶层的工作流引擎上进行合作。因此,我们有一种堆叠式架构(stacked architecture),它与深度学习全景周围的所有不同群体进行合作。」
Stevens 说:「有趣的是下一代平台的供应商强烈支持提高机器学习所需的架构理念和功能,以及传统的物理驱动仿真(physics-driven simulation)。」他指出,与传统 HPC 相比,深度学习的快速增长和市场压力正在推动它们朝着这个方向发展。「它也让我们洞察到了 DOE 应用的发展方向:将需要传统的物理驱动的仿真的地方,但通常我们也可以找到一个利用机器学习的方法。」
共享学习是试点项目的重要组成部分。Stevens 说:「我们正在为机器学习社区抽象模型问题,这也是我们正在研究的 seven candle benchmarks 的一种净化版本,」这将包括可分布式的数据、代码,这些内容都 将在 GitHub 上开放。这些元素的第一部分预计会在第二季度发行。
个别试点小组也正在与学术界开展自己的外联活动。在试点项目计算能力的方面,「我们瞄准了一些平台,特别是 CORAL 平台、Oak Ridge 和 Livermore 的新机器,然后最终选定百亿亿次(exascale)级。这是一个普遍化的概念,所以它不是具体的 GPU 或者具体的多少核。」
有趣的是,这三个项目计划会用不同的方式使用深度学习。
因为 RAS 是在分子尺度上的项目,所以它在所有项目中拥有最小尺寸规模。你可能听说过 RAS,它是一个著名的癌症基因,其编码会生成嵌入在细胞膜中信号蛋白(signaling protein)。这些蛋白质控制着可以延伸到细胞中并驱动许多不同的细胞过程的信号传导途径。RAS 目前涉及约 30% 的癌症,包括一些最棘手的癌症,例如胰腺癌。该试点项目将把模拟和湿实验室筛选数据进行结合,以详细阐述 RAS 相关信号级联的细节,并且希望可以找到用于制造能干预这种病症所使用的新药的关键点。
即使一个相对较小的肿瘤也可能有「成千上万个突变,包括驱动突变(driver mutation)和许多偶然突变(passenger mutation),」Stevens 说。这些遗传差异会改变信令网络(signaling network)的重要细节信息。多年来,RAS 本身及其相关信令网已经成为药物靶点,但正如 Stevens 指出的:「这种信令网的行为很不直观。有时如果你击中了其中一个下游组分,它其实会产生负反馈,这实际上增加了你试图去抑制的效果。」
在 RAS 项目中,仿真基本上是一种在不同粒度(一直延伸到到原子行为,包括量子效应)上进行的分子动力学运动。所需的计算能力(会非常巨大)自然取决于所仿真的粒度水平。
「机器学习被用于跟踪仿真所经历的状态空间(state space),并进行决策——这里是否放大、是否缩小、是否改变我们在集合空间(ensemble space)的不同部分中所观察的参数。它基本上像是该仿真的一个智能监督人那样去更有效地使用它。
「从某种意义上讲,这就像是网络正在观看一部电影并且说道,『好吧,我之前已经看过电影的这个部分了,让我们快进吧,或是哇这真有趣,我之前从来没见过,让我们用慢镜头并放大看。』这种就是机器学习在模拟中所做的事情。在某种意义上,它能够快进并且跳过,「Stevens 说。由 Stevens 领导的这个临床前筛选项目是一个雄心勃勃的尝试,它基本上是从所能得到的尽可能多的临床前及临床癌症数据中进行精筛,并与小鼠模型中产生的新数据结合来建立药物-肿瘤相互作用的预测模型。这是一种生物信息学的和实验性的反馈方法。最终,给定一个特定肿瘤,其分子属性(基因表达、单核苷酸的多态性(Single Nucleotide Polymorphisms/SNP)、蛋白质组学等)已被确定,那么将该数据插到模型中来确定最佳治疗方案就应该是可以实现的。
此处的微妙之处在于,这种在单一类肿瘤或相对小门类药物上进行的小规模机器学习工作已做了很多,Stevens 说。「我们正在尝试使用深度学习来整合所有对象(成千上万的细胞系以及从较小数量细胞系中筛选出的化合物)的信息,然后就能将其应用在实验鼠身上。你培养了一群源自该人类肿瘤的实验鼠,而这些小鼠会成为人类临床试验的替代物。因此我可以在肿瘤鼠群体中尝试不同化合物来提供信息——我的肿瘤对给定药物可能会如何反应。」
一个巨大的挑战来自于是否能够理解所有历史数据,其中大部分数据是非结构化的,且往往是主观的(如病理报告)。「我们所做的第一件事情之一是建立分类器,它可以告诉我们该肿瘤的类型或者是它在身体的哪个部位(根据不同的数据),」他说。数据可疑的情况并不少见。「我们通过我们的分类器来运行它,而如果它是一个新的数据集,那么分类器就可能会说,它真不是来自肝脏,它来自一些其他部位。」通常临床前数据是基于结果的;它不会解释该结果是如何实现的。
「现在我们所建立的机器学习模型能够十分精确地预测出一个药物反应或肿瘤类型/结果,但它们不能相当有效地告诉我们个中原因。它们不是解释性的,不是机械论的,」Stevens 说,「我们要做的是以某种方式带来一些机械论的模型或机械论的数据,并将其与机器学习模型混合从而得到两样东西——拥有高精度预测能力的模型以及拥有预测解释能力的模型。因此这种混合方法的思想是一个宽广的开放空间,而我们认为这将会被推广到许多领域。」获得大而高质量的训练模型数据仍然具有挑战性,他说。
第三个项目致力于开发可预测人口规模的模型,Stevens 称之为「病人轨迹(patient trajectories)」,它基本上是在挖掘全国的监控数据。虽然该数据有些分散,但美国国家癌症研究所(National Cancer Institute/NCI)、美国国立卫生研究院(National Institutes of Health/NIH)、美国食品和药物管理局(Food and Drug Administration/FDA)、制药公司和付款人组织(病理报告、疗法、结果、生活方式、人口统计等)所持有的病人数据体量却十分庞大。不幸的是,在很大程度上它像许多生物医学数据一样是非结构化的。「我们不能真正以我们所希望的方式用它进行计算,因此我们正在使用机器学习来将非结构化数据翻译成我们可用于计算的结构化数据,」Stevens 说。
「因此,例如我们想用一台机器来读取所有病理报告并输出生物标记物(biomarkers)、突变状态或药物之类的信息,这样我们才能创建出具有一致性的病例报告。将它看做是一个以人口为基础的模型。在临床前筛选试点项目中,比如我们发现了一些对治疗某一类癌症非常有效的疗法和策略。我们想提取这些信息并将其输入到人口模型中,并说『如果这成为一种常见疗法的话,那么它在全球或全国范围内会对统计数字有多少改变?』或类似的话。」
这也是一种连接所有试点项目的方法,Stevens 说。从 RAS 项目中获得的认识以后可能会被用于观察那些或许适用于新疗法的一部分癌症;再反过来把它纳入人口模型项目中以了解可能会产生的影响。
JDACS4C 试点项目仍处在初期阶段,但希望很高。Stevens 指出,NCI 和 DOE 都获得了它们无法轻易获得的东西。「NCI 没有 DOE 所拥有的众多数学家和计算机科学家。他们也没办法使用最领先的机器。我们(DOE)所获得的是访问所有这些伟大的实验数据、实验设施和公共数据库的权限。」